
1. Introduction:
A query is a request for information from a database. A query plan (or query execution plan) is an ordered set of steps used to access data in a SQL relational database management system.
A single query can be executed through different algorithms or re-written in various forms and structures. Hence, the question of query optimization comes into the picture – Which of these forms or pathways is the most optimal? The query optimizer attempts to determine the most efficient way to execute a given query by considering the possible query plans.
2. The Goal of Query Optimization
Query optimization is the process of choosing the most efficient means of executing a SQL statement. Fixing and preventing performance problems is critical to the success of any application. The goal of query optimization is to reduce the resource required to fulfill a query each of these plans, and selects the plan with the lowest cost of the and ultimately provide the user with the correct result set faster.
We will use a variety of tools and best practices to provide a set of techniques that can be used to analyze and speed up any performance problem.
3. What will optimize the query?
The SQL Server Query Optimizer will do the magic of optimizing the query. It is a cost-based optimizer. It analyzes several candidate executions plans for a given query, estimates the cost of each of these plans and select the plan with the lowest cost of the choices considered.
The query optimizer is the built-in database software that determines the most efficient method of a SQL statement to access requested data.
There are many query optimization techniques available like below,
1. Essential Indexing
2. Retrieve the relevant data only
3. Getting rid of correlated subqueries
4. Using or avoiding temporary tables
5. Avoid coding loops
6. Execution plans
In this article, we will see essential indexing techniques.
4. Essential Indexing Techniques
Indexing is a way to optimize the performance of a database by minimizing the number of disk accesses required when a query is processed. Indexes are created using some columns from the table.
It is a type of data structure technique, and it is used to quickly locate and access the data in a database.
4.1. Index structure
SQL Server indexes are created to speed up the retrieval of data from the database table or view. Below is the index structure.

A Non-clustered index stores the data at one location and indices at another location. The index contains pointers to the location of that data. A single table can have many non-clustered indexes as an index in the non-clustered index is stored in different places.
As developers and DBAs, there are aspects about SQL Server that we need to understand to see how SQL Server goes about using indexes. Below are a few indexing techniques.
1. Unused Index
2. Duplicate Index
3. Missing Index
4. Seek vs. Scan
5. Bookmark Lookup
6. Index on Computed Columns
7. Indexing Best Practices
4.2. Unused Index
Unused indexes are data structures, which are sitting inside SQL Server, which consume unnecessary disk space and are hardly getting used. It may cause get less efficient execution plan and a reduction in overall server performance.
Using below query DMV(Dynamic Management Views), we can identify the unused indexes inside SQL Server.
SELECT
o.name AS TableName,
i.name AS Indexname,
i.is_primary_key AS PrimaryKey,
s.user_seeks + s.user_scans + s.user_lookups AS NumOfReads,
s.user_updates AS NumOfWrites,
(SELECT SUM(p.rows) FROM sys.partitions p WHERE p.index_id = s.index_id AND s.object_id = p.object_id) AS TableRows,
'DROP INDEX ' + QUOTENAME(i.name) + ' ON ' + QUOTENAME(c.name) + '.' + QUOTENAME(OBJECT_NAME(s.object_id)) AS 'DropStatement'
FROM sys.dm_db_index_usage_stats s
INNER JOIN sys.indexes i ON i.index_id = s.index_id AND s.object_id = i.object_id
INNER JOIN sys.objects o ON s.object_id = o.object_id
INNER JOIN sys.schemAS c ON o.schema_id = c.schema_id
WHERE OBJECTPROPERTY(s.object_id,'IsUserTable') = 1
AND s.databASe_id = DB_ID()
AND i.type_desc = 'NONCLUSTERED'
AND i.is_primary_key = 0
AND i.is_unique_constraint = 0
Best Practice: Drop Unused Indexes
4.3. Duplicate Index
Reduces the performance of INSERT, UPDATE, DELETE Query. There is no performance advantage to SELECT statements, and it’s wasteful of space for SQL Server, and hence, for large databases and large tables, this is going to occupy a lot of rows.
Using the below DMV query, we can identify the duplicate indexes inside SQL Server.
SELECT
s.Name + '.' + t.Name AS TableName
,i.name AS IndexName1
,DupliIDX.name AS IndexName2
,c.name AS ColumnNae
FROM sys.tables AS t
JOIN sys.indexes AS i
ON t.object_id = i.object_id
JOIN sys.index_columns ic
ON ic.object_id = i.object_id
AND ic.index_id = i.index_id
AND ic.index_column_id = 1
JOIN sys.columns AS c
ON c.object_id = ic.object_id
AND c.column_id = ic.column_id
JOIN sys.schemas AS s
ON t.schema_id = s.schema_id
CROSS APPLY
(
SELECT
ind.index_id
,ind.name
FROM sys.indexes AS ind
JOIN sys.index_columns AS ico
ON ico.object_id = ind.object_id
AND ico.index_id = ind.index_id
AND ico.index_column_id = 1
WHERE ind.object_id = i.object_id
AND ind.index_id > i.index_id
AND ico.column_id = ic.column_id
) DupliIDX
ORDER BY
s.name,t.name,i.index_id
Best Practice: Drop Duplicate Indexes
4.4. Missing Index
Whenever you look at workloads coming into SQL Server over a period, SQL Server will start spitting out missing indexes. Create a non-clustered index on the table if necessary. Creating the appropriate indexes based on the workload that comes in is one of the most critical aspects of any performance tuning up the tip.
Wherever possible, create narrow width indexes, and it is always preferred. Column order indexes are significant because these can become a vital requirement for the workload that comes in.
Using the below DMV query, we can identify the missing indexes inside SQL Server.
SELECT
d.[object_id],
s = OBJECT_SCHEMA_NAME(d.[object_id]),
o = OBJECT_NAME(d.[object_id]),
d.equality_columns,
d.inequality_columns,
d.included_columns,
s.unique_compiles,
s.user_seeks, s.last_user_seek,
s.user_scans, s.last_user_scan
FROM sys.dm_db_missing_index_details AS d
INNER JOIN sys.dm_db_missing_index_groups AS g
ON d.index_handle = g.index_handle
INNER JOIN sys.dm_db_missing_index_group_stats AS s
ON g.index_group_handle = s.group_handle
WHERE d.database_id = DB_ID()
AND OBJECTPROPERTY(d.[object_id], 'IsMsShipped') = 0;
Best Practice: Create Missing Indexes
4.5. Scan vs. Seek
4.5.1. Scan
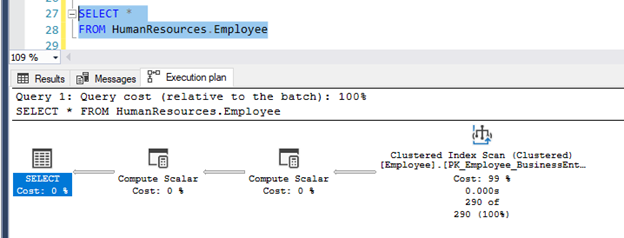
Index scan means that the search will touch all rows in the table, if needed or not, with the cost proportional to the number of rows in the table. It is not a bad issue if you have a small table with few numbers of records.
The below example query is doing a clustered index scan. The table ‘HumanResources.Employee’ has a clustered index, and there is not a WHERE clause, so SQL Server scans the entire clustered index to return all rows.
In the same way, when the table does not have a clustered index and there is not a WHERE clause, SQL Server scans the entire table to return all rows, and it is called a Table scan. This will also reduce the performance of the query.
4.5.2. Seek
Seek uses the index to pinpoint the records that are needed to satisfy the query. When a search criterion matches an index well enough that the index can navigate directly to a particular point in your data, that’s called an index seek.
In the below example, the ‘NationalIdNumber’ column has a non-clustered index. So, the execution plan shows the Index Seek operator. This will increase the performance of the query.
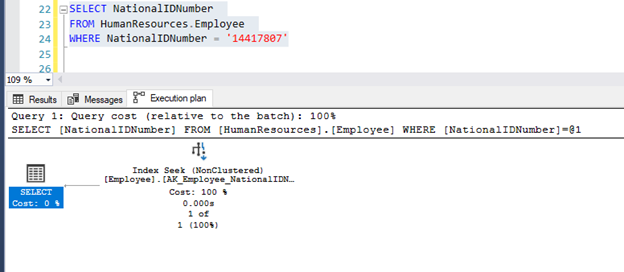
Generally, seeks are good, scans are bad. If the table is small and contains a smaller number of records, the index scan won’t affect query performance that much.
4.6. Lookup
One of the easiest things to fix in performance tuning queries is Key Lookups and RID Lookups. A Key Lookup occurs when the table has a clustered index, and a RID lookup occurs when the table does not have a clustered index.
When will Key Lookup occur? A Key Lookup occurs when data is found in a non-clustered index, but additional data is needed from the column which has no index to satisfy the query, and therefore lookup occurs.
A Key lookup is a very expensive operation because it performs a random I/O into the clustered index. So, in most cases, we need to avoid lookup to improve the query performance.
In the below example, SQL server doing an index seek based on non-clustered index ‘NationalIdNumber.’ Here ‘HireDate’ and ‘MaritialStatus’ are in the output list, but a non-clustered index is not created for these columns so that the key lookup operator gets created in the execution plan.
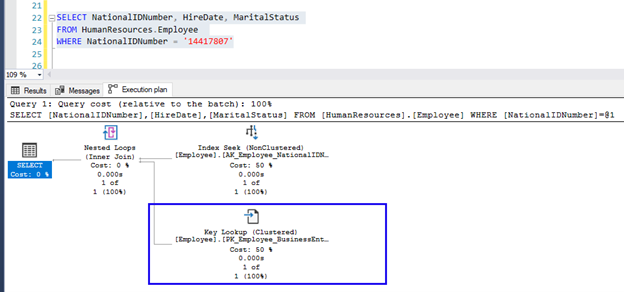
To avoid the key lookup, we need to cover the non-clustered index for the columns ‘HireDate’ and ‘MaritalStatus.’
CREATE INDEX [IX_HumanResources_Employee_Example]
ON HumanResources.Employee (NationalIdNumber)
INCLUDE (HireDate, MaritalStatus)
GO
Now for the same query, lookup seems to have vanished. One of the ways in which you can make them vanish is by covering non-clustered index for the columns which is in the select list.
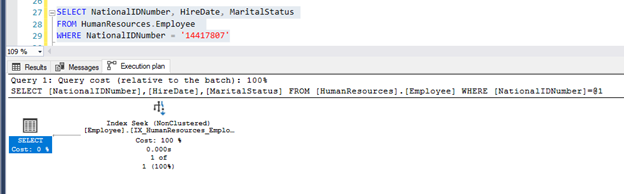
It is always a good practice to look at the most selective column as the first column. Column order for the index is very important.
4.7. Index on computed columns
Using SQL Server built-in function in the WHERE clause usually reduces the query performance. If we really need to apply the SQL Server function on the column, we can create a separate computed column and add a non-clustered index for that column like below.
ALTER TABLE dbo.UDFEffect ADD
CityTrim AS RTRIM(LTRIM(City))
GO
CREATE NONCLUSTERED INDEX IX_UDFEffect_ID_City
ON UDFEffect(Id, CityTrim)
GO
We can use this computed column in the WHERE clause like below. This will result in the index seek operator in the execution plan.
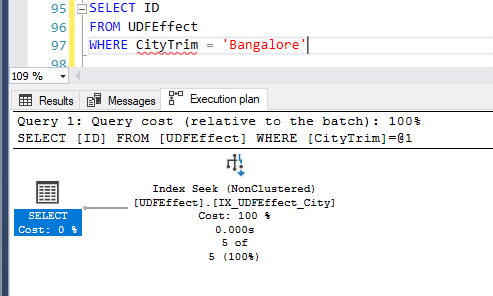
4.8. Index best practices
1. Create a narrow index
a. Try to use included index
2. Prefer integer column for index
3. Use most selective columns as the first column
4. Avoid using the function in the WHERE clause
4.8.1. Create narrow index
Trying to use included index is also called a covering index. Indexes with included columns provide the greatest benefit when covering the query.
Performance gains are achieved, and the query optimizer can locate all the column values within the index in fewer disk I/O operations. However, having too many included columns may increase the time required to perform insert, update, or delete operations to your table.
Let’s look at the same example. The below query returns the execution plan with the lookup operator because the ‘HireDate’ and ‘MaritalStatus’ columns don’t have an index.
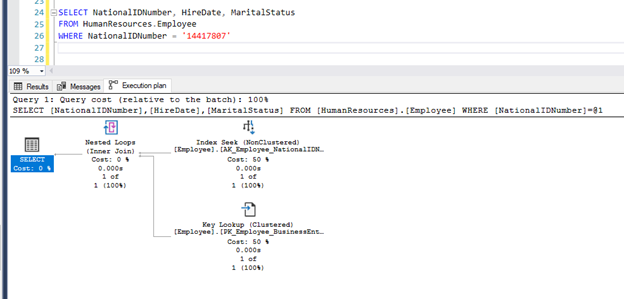
We could add ‘HireDate’ and ‘MaritalStatus’ as an included index like below.
CREATE INDEX [IX_HumanResources_Employee_Example]
ON HumanResources.Employee (NationalIdNumber)
INCLUDE (HireDate, MaritalStatus)
After adding those columns as an included index, Key Lookup gets resolved.
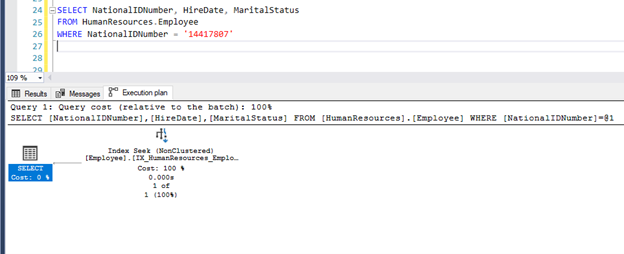
4.8.2. Prefer integer column for index
Int comparisons are faster than varchar comparisons, for the simple fact that int takes up much less space than varchars.
The fastest way to go is an indexed int column.
4.8.3. Most selective column first
Every time a composite index is created, the order of the columns in a composite index does matter on how a query against a table will use it or not. A query will use a composite index only if where clause of the query has at least the leading/left-most columns of the index in it.
4.8.4. Avoid using function in WHERE clause
As an index best practice, we need to avoid using the function in the WHERE clause. This usually pulls down the query performance. If we really want to use the function, create a computed column based on the function and add it as part of this table and use the computed column in the WHERE clause. This will solve the query performance issue.
Badly designed SQL Server indexes or missing ones are the main cause of the slowness in most environments. Plan and study deeply, test many scenarios, and finally, decide which one is suitable for your situation. Review the index usage regularly to remove unused indexes and plan to add the missing ones.
5. Conclusion:
So, we learned that how indexing can improve the performance of the query drastically. This will boost the performance of applications providing a better user experience. Keep all the guidelines in mind while writing queries.